

漏洞概要 关注数(24) 关注此漏洞
缺陷编号:wooyun-2015-0162491
漏洞标题:HR家十万级别简历下载(包含联系方式,学历,工作经历等信息)
相关厂商:HR家(杭州麦积科技有限公司)
漏洞作者: 蓝蓝的白云
提交时间:2015-12-19 16:56
修复时间:2016-02-04 17:47
公开时间:2016-02-04 17:47
漏洞类型:敏感信息泄露
危害等级:高
自评Rank:10
漏洞状态:已交由第三方合作机构(cncert国家互联网应急中心)处理
漏洞来源: http://www.wooyun.org,如有疑问或需要帮助请联系 [email protected]
Tags标签: 无

漏洞详情
披露状态:
2015-12-19: 细节已通知厂商并且等待厂商处理中
2015-12-23: 厂商已经确认,细节仅向厂商公开
2016-01-02: 细节向核心白帽子及相关领域专家公开
2016-01-12: 细节向普通白帽子公开
2016-01-22: 细节向实习白帽子公开
2016-02-04: 细节向公众公开
简要描述:
网站应该有数十万份简历(从id判断的,虽然其中很多质量不高)。可以通过批量搜索下载到包含联系方式、学历、工作经历等信息的简历。成因主要有两个:一个是简单修改即可实现批量搜索;第二个是搜索的结果本来不应该返回联系方式等重要信息。
唯一的限制是每个关键词搜索似乎只能返回前5000个简历,所以只能通过尝试各种关键词搜索才有可能下载到几万或者几十万份简历。
虽然这本来就是(多少有点不道德的)涉嫌倒卖个人信息的网站,但原本还是隐藏了联系方式,要交钱或者上传(未经授权传播的)简历才能显示联系方式。谴责归谴责,还是希望他们早日完善网站安全,以免这些简历遭到更广泛的传播。
详细说明:
“HR家”网站(http://**.**.**.**)的本意是搜索时看不到联系方式,想要看联系方式需要充值或者上传其他人的简历。
但是实现时有至少以下三个安全问题,导致可以批量查询下载:
首先,搜索简历时页面上虽然只显示出工作经历,但实际上已经把包含联系方式的完整简历传输到本地了。这导致了简历的联系方式可以被无联系方式查看权限的企业用户看到。
其次,虽然每次搜索只返回十条结果,但是通过简单改动就可以实现批量查询。这使得简历可以被企业用户批量获取。
最后,虽然理论上只有企业可以搜索,但实际上只要有手机号就可以注册并搜索下载简历。这使得简历可以被任何人批量获取。
漏洞证明:
Step 01~03 打开网站并注册登录。网址是http://**.**.**.**(可能.com的域名是不是新版网站)。注册时要选择“我有坑”注册企业账号才能搜索简历,资料可以乱填,只需要手机接收验证码。
这是首页
这是注册页面
这是注册登陆后的主页,注意点击搜索框进入搜索页面。
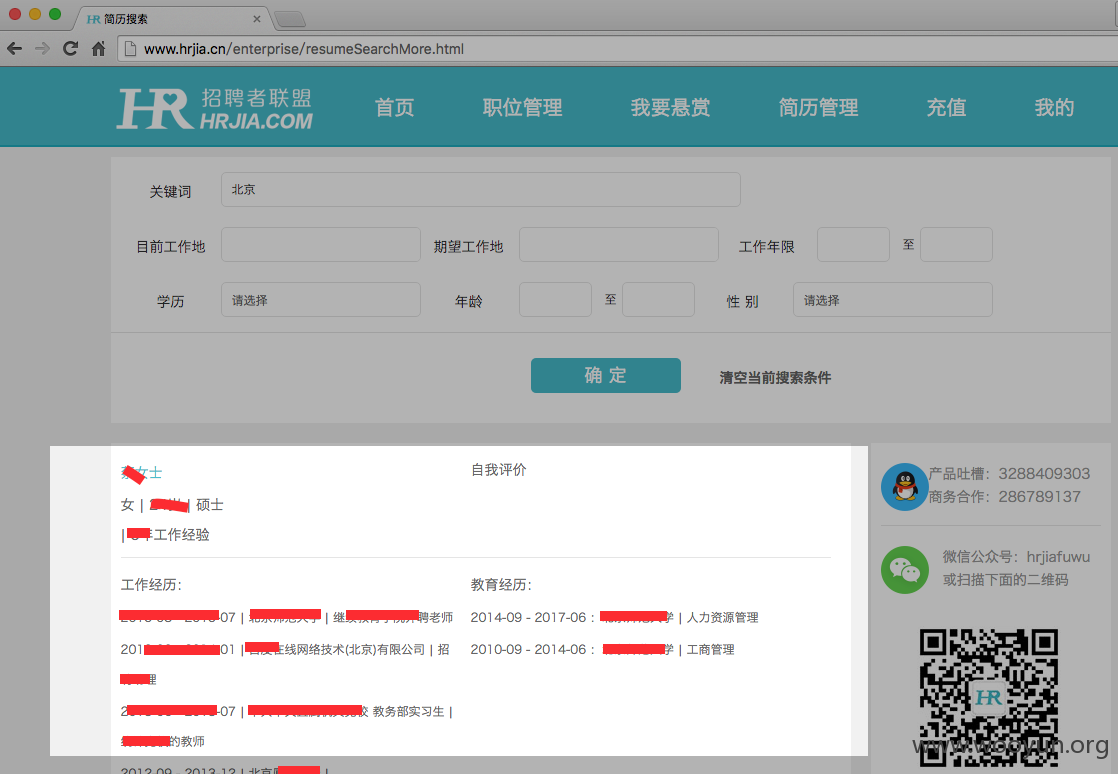
Step 04 搜索简历。关键词可以是上海,北京,C++,行政等等。
这是搜索页面,注意我们其实只需要一个可以接收验证码的手机就可以随意搜索别人的简历了,完全不需要专业知识。比如你想知道某个同学这几年在哪混,某个同事期望薪资多少,某个上司的学历和过往背景,花个几分钟搜索就可以了解。如果你的简历不幸在这几十万份之中,即使将来修正了漏洞,只要他们商业模式不改变,隐私仍然会像这样被泄漏。
Step 05 查看数据包。在step 04的搜索页面打开Chrome的开发者工具,切换到network tab,然后进行一次搜索。

图上这个resumeSearch就是问题的关键。双击可以看到具体信息。
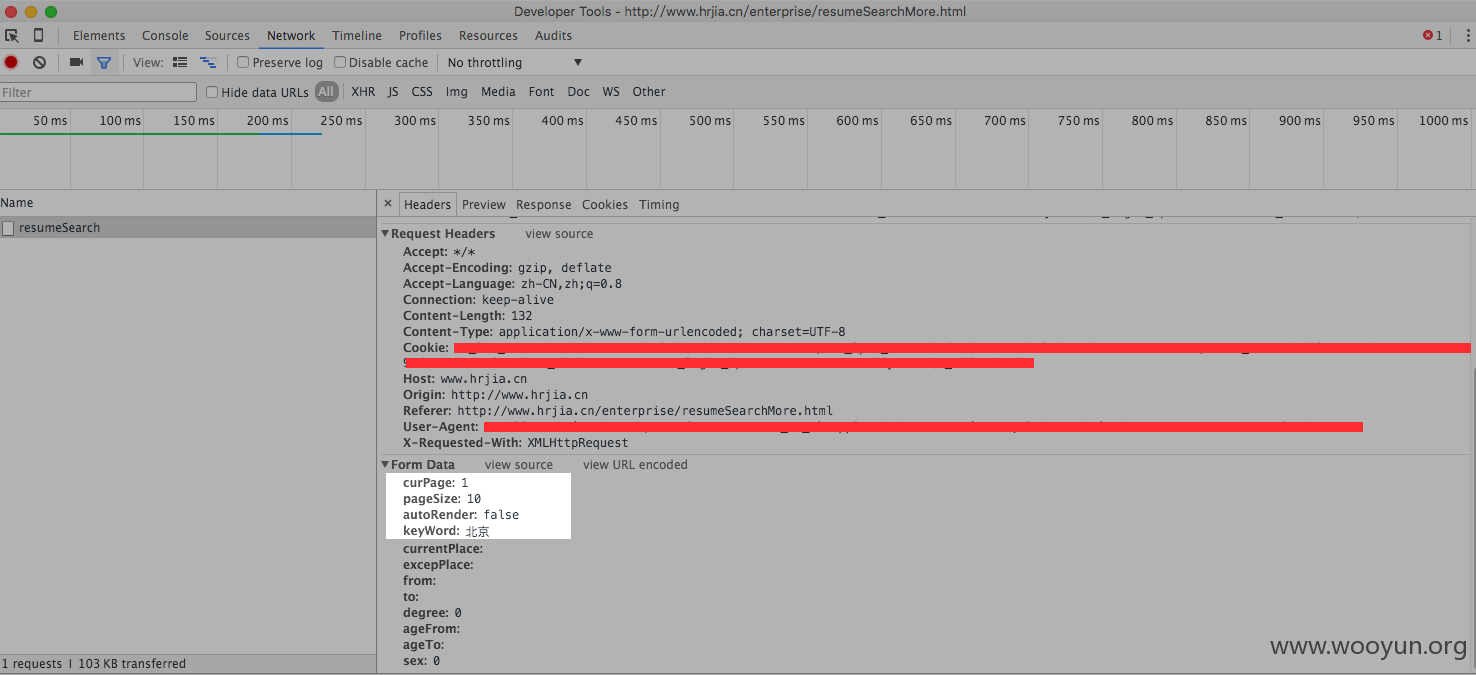
这是数据包的头部和form data。注意有curPage和pageSize。
Step 06 查看数据包返回的信息。开发者工具从Headers tab切换到Preview tab。
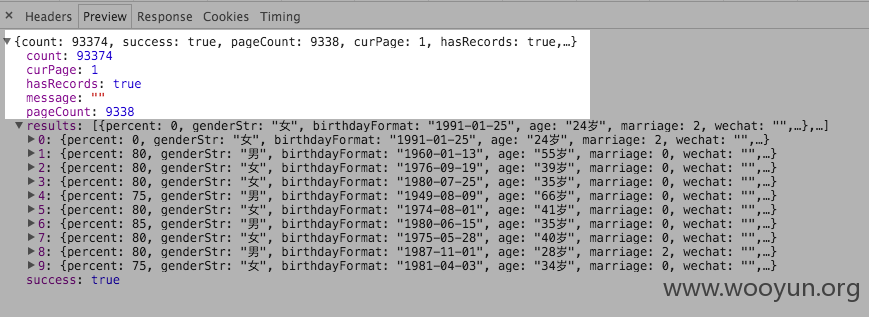
从上图可以看到,执行搜索的时候返回了总人数和总页数,以及这一分页上的简历信息(默认10条一页)。
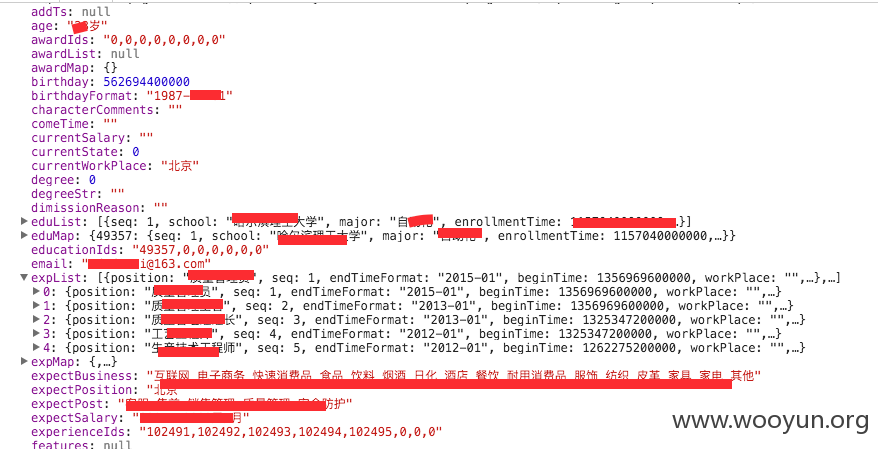

上面两张图是简历信息的具体内容,包括电话、邮箱、过往工作经历、教育经历、姓(没有名)、性别以及其它信息。这些简历似乎是从其他网站下载后导入的,字段很多,有些人填得更全,有些人缺失信息比较多。
Step 07 导出cURL。在开发者工具的resumeSearch上右击,选择Copy as cURL。这个导出的直接是CURL命令,可以在命令行直接粘贴执行,执行的输出就是10条简历信息。
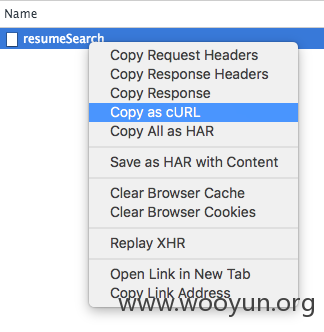
Step 08 修改cURL,实现批量查询。这个方法多了,我就随便贴一下(把cookie等替换掉即可)。
似乎只能获取搜索结果前500页的内容。我试过直接在网页上翻页只能翻500页。但是500页就有5000份简历,通过不同关键词组合搜索,花点时间应该可以把这几十万份简历全部弄下来。
最后是一小段下载下来的简历,做过模糊处理了。

修复方案:
他们似乎在重新做新的网站了。至少这个老的站问题应该还挺多。我是菜鸟,只找到这个笨途径下载简历。
如果新网站没问题,老的站可以直接关掉。
版权声明:转载请注明来源 蓝蓝的白云@乌云
漏洞回应
厂商回应:
危害等级:中
漏洞Rank:10
确认时间:2015-12-23 20:06
厂商回复:
CNVD未直接复现所述情况,已由CNVD通过软件生产厂商公开联系渠道向其邮件通报,由其后续提供解决方案并协调相关用户单位处置。
最新状态:
暂无